BFD, which stands for Bidirectional Forwarding Detection, is a protocol used to detect faults within a network. Specifically, it is used to detect faults between two forwarding engines connected by a link. BFD can provide rapid failure detection times for all media types, encapsulations, topologies, and routing protocols.
Yes, BFD can and often is used in conjunction with the Border Gateway Protocol (BGP), another important protocol used to exchange routing information across autonomous systems in the internet. When BFD is used with BGP, it allows for much faster detection of path failures than would be possible with BGP alone, thus helping to improve network stability and resilience.
The settings for BFD when used with BGP will largely depend on your specific network requirements. However, here are some general recommendations:
1. BFD Interval: This is the frequency with which BFD control packets are sent. A common setting is 300 milliseconds, but you can lower this to speed up failure detection at the cost of higher network traffic.
2. BFD Multiplier: This determines how many missed BFD control packets will be tolerated before a link is considered down. A common setting is 3, but you can increase this if you have a flaky connection that occasionally drops packets.
3. BGP Timers: When using BFD with BGP, it’s recommended to set the BGP keepalive and hold timers to a high value (like 60 seconds for keepalive and 180 seconds for hold time). This is because the rapid failure detection provided by BFD makes the faster BGP timers less necessary.
Here is an example configuration for Cisco routers:
Router(config)# interface GigabitEthernet0/0 Router(config-if)# bfd interval 300 min_rx 300 multiplier 3 Router(config-if)# exit Router(config)# router bgp 65001 Router(config-router)# neighbor 192.0.2.2 fall-over bfd Router(config-router)# timers bgp 60 180
Remember, these settings should be adjusted based on your network’s specific needs and constraints. Always test configurations in a lab environment before deploying them in a production network.
CONTROL PLANE VS FORWARDING PLANE
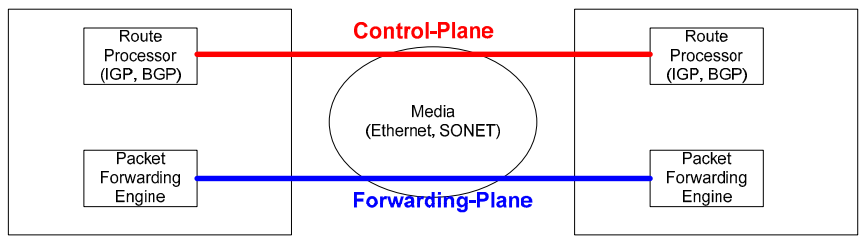
The control plane and forwarding (or data) plane are critical components of networking devices like routers and switches. They play different but complementary roles in network operation:
1. Control Plane: This is responsible for the network-wide decision-making process, particularly around how data should be forwarded. Protocols like BGP, OSPF, and others operate at the control plane level. They exchange routing information, build data structures (like routing tables), and apply policies that determine the path traffic takes through the network. In the case of BFD and BGP, BGP operates on the control plane to establish and maintain network paths, while BFD helps ensure these paths are reliable by detecting link failures.
2. Forwarding Plane (Data Plane): The forwarding plane is responsible for actually moving packets from a device’s input to the appropriate output based on decisions made by the control plane. For instance, once the control plane has determined the best path for a packet based on the routing table, the forwarding plane takes over and sends the packet along the correct interface.
In summary, the control plane makes the decisions, and the forwarding plane executes those decisions.
BFD, while not being a routing protocol, still has components that function on both the control and data planes. BFD control packets are generated and processed by the control plane, while their transmission and reception (especially the detection of lost packets) occur in the data plane. This dual-plane operation allows BFD to provide rapid fault detection and make networks more robust and resilient.
DATA FLOW
BFD (Bidirectional Forwarding Detection) provides a low-overhead, short-duration method for the detection of failures in the path between adjacent forwarding engines, including the interfaces, data links, and intermediate forwarding engines.
From a packet perspective, here’s a simplified view of how the data flow works:
1. BFD Session Initialization: When two devices want to monitor each other for reachability, they first initialize a BFD session. This involves exchanging control packets to agree on parameters like the desired transmission and detection intervals.
2. Transmission of BFD Control Packets: Once the session is established, the devices start periodically sending BFD control packets to each other. These are small packets containing only a header and possibly some optional authentication data. The frequency of these control packets is determined by the agreed-upon transmission interval.
3. Receipt and Acknowledgment of BFD Control Packets: When a device receives a BFD control packet, it acknowledges this by updating the information it sends in its own BFD control packets. Specifically, it updates the “Your Discriminator” field to match the “My Discriminator” field of the received packet. This way, each device knows the other is receiving its control packets.
4. Detection of Failures: If a device stops receiving BFD control packets from its peer for a duration longer than the agreed-upon detection interval, it concludes that the path to the peer is down. It can then inform the higher-layer protocols (like BGP) so they can react accordingly.
The beauty of BFD is its simplicity. By using lightweight control packets and a straightforward detection mechanism, it provides rapid failure detection with minimal overhead. This helps improve the reliability and responsiveness of networks, particularly those using complex routing protocols like BGP.
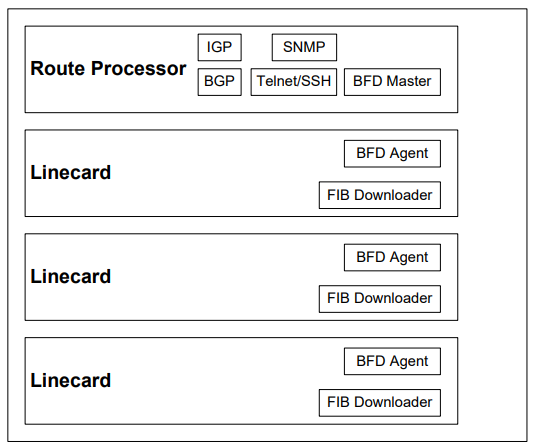
ARCHITECTURE
WHAT PROTOCOLS WORK WITH BFD
Bidirectional Forwarding Detection (BFD) is typically used with routing protocols to provide faster detection of link failures. The most commonly used routing protocols with BFD are:
1. Border Gateway Protocol (BGP): As an inter-autonomous system routing protocol, BGP is often used with BFD to quickly detect failures in the network. BGP can then reroute traffic to alternative paths, ensuring network connectivity.
2. Open Shortest Path First (OSPF): OSPF, an interior gateway protocol used to distribute routing information within a single autonomous system, can benefit from BFD’s fast link-failure detection. OSPF can then more quickly adjust its internal routing tables.
3. Intermediate System to Intermediate System (IS-IS): Similar to OSPF, IS-IS is an interior gateway protocol that can use BFD for rapid failure detection.
4. Routing Information Protocol (RIP): While not as common as OSPF or BGP, RIP can also use BFD for failure detection.
5. Multiprotocol Label Switching (MPLS): BFD can also be used with MPLS to detect failures in label-switched paths.
6. EIGRP (Enhanced Interior Gateway Routing Protocol): This Cisco proprietary protocol can also be paired with BFD for fast failure detection and route adjustments.
In general, BFD can be used with any protocol that needs to rapidly detect failures in the path between two systems. The use of BFD is not limited to routing protocols; it can also be used with other types of protocols depending on the specific needs of the network.