When designing a Cisco ACI (Application Centric Infrastructure) solution, there are different deployment options available, each with its own pros and cons. Here are the commonly used options:
- Single-Pod Design:
In a single-pod design, all the ACI fabric components (spine switches, leaf switches, and APIC controllers) are deployed within a single data center pod.
Pros:
- Simplified deployment: Single-pod design offers a straightforward deployment model, especially for smaller data center environments.
- Lower latency: Since all components are within a single pod, communication latency between switches and controllers is minimal.
Cons:
- Limited scalability: Single-pod design may have limitations in terms of scalability and capacity for larger and more complex data center deployments.
- Lack of redundancy: If a single pod fails, there may be a complete loss of connectivity and services.
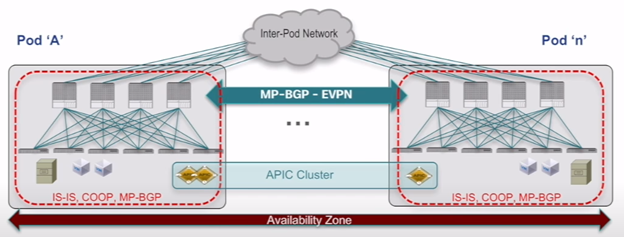
- Multi-Pod Design:
In a multi-pod design, multiple data center pods are interconnected to form a larger ACI fabric. Each pod has its own set of fabric components.
Pros:
- Scalability: Multi-pod design enables the expansion of ACI fabric to accommodate larger data center deployments with increased capacity and scalability.
- Redundancy: Multiple pods provide built-in redundancy. If one pod fails, traffic can be redirected to other pods, ensuring high availability.
Cons:
- Increased complexity: Multi-pod design introduces additional complexity in terms of interconnecting pods, maintaining consistent policies, and managing a larger fabric.
- Higher latency: Inter-pod communication introduces additional latency compared to a single-pod design.
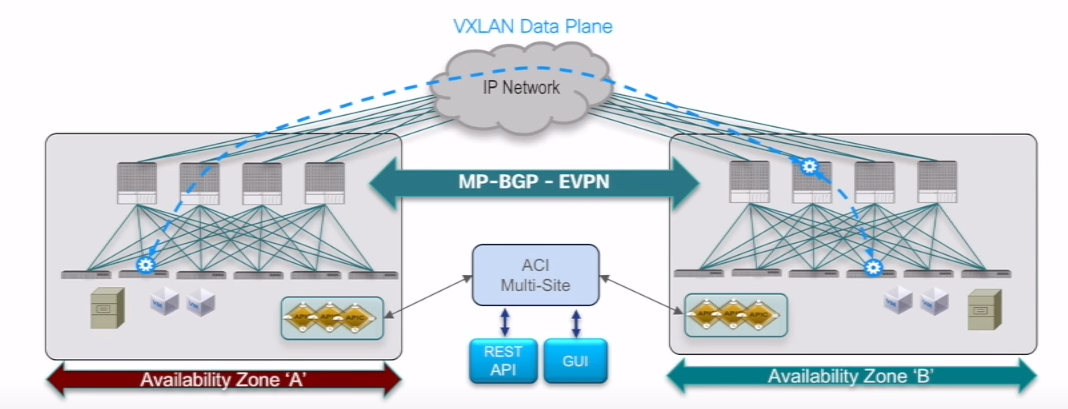
- Multi-Site Design:
In a multi-site design, multiple ACI fabrics are deployed across geographically dispersed data center sites. Each site has its own set of fabric components.
Pros:
- Disaster recovery: Multi-site design enables the implementation of disaster recovery and business continuity strategies. If one site goes down, traffic can be redirected to other sites.
- Geographical distribution: Multi-site design allows for closer proximity to users or to support distributed applications.
Cons:
- Increased complexity: Multi-site design introduces complexity in terms of interconnecting sites, maintaining consistent policies across sites, and managing distributed deployments.
- Higher latency: Inter-site communication introduces additional latency compared to a single-pod or multi-pod design.
- ACI Anywhere:
ACI Anywhere extends the ACI fabric beyond the traditional data center environment to public clouds (such as AWS or Azure) and remote branches.
Pros:
- Consistent policy enforcement: ACI Anywhere allows for consistent policy enforcement across on-premises data centers and public cloud deployments, providing a unified management experience.
- Flexibility and hybrid cloud support: ACI Anywhere enables workload mobility between on-premises and public cloud environments, offering flexibility and supporting hybrid cloud architectures.
Cons:
- Connectivity and latency considerations: Extending ACI to public clouds or remote branches requires appropriate connectivity solutions, and network latency may be a concern depending on the distance and connection quality.
When selecting an ACI design option, it’s essential to consider factors such as the size and complexity of the data center, scalability requirements, redundancy needs, geographical distribution, disaster recovery plans, and cloud integration strategies. The chosen design should align with the specific goals, constraints, and operational requirements of the organization.
CONTROL PLANE vs DATA PLANE (BGP/VXLAN)
Let’s dive into details about the control plane and data plane in Cisco ACI, as well as how VXLAN and MP-BGP are utilized within the framework:
- Control Plane:
In Cisco ACI, the control plane is responsible for managing and maintaining the overall operation of the fabric. It involves the exchange of control information between various ACI fabric components, including the APIC controllers and the fabric switches.
- APIC Controllers: The Application Policy Infrastructure Controllers (APICs) act as the central control plane of the ACI fabric. They provide a unified management and policy enforcement interface for the entire fabric.
- Discovery and Communication: The APIC controllers use a discovery process to identify and communicate with the fabric switches (spine and leaf switches). They establish and maintain communication channels to exchange information such as fabric topology, policies, endpoint information, and forwarding instructions.
- Policy Distribution: The APIC controllers distribute policies to the fabric switches, ensuring consistent policy enforcement throughout the fabric. They utilize a publish-subscribe model to propagate policy updates and maintain policy synchronization across all switches.
- Data Plane:
The data plane in Cisco ACI is responsible for forwarding network traffic within the fabric. It involves the encapsulation and forwarding of packets between endpoints across the ACI fabric.
- VXLAN Encapsulation: Cisco ACI uses the VXLAN (Virtual Extensible LAN) protocol for overlay networking. VXLAN encapsulates the original Ethernet frames within UDP (User Datagram Protocol) packets, adding a VXLAN header that contains a unique VXLAN Network Identifier (VNI).
- Endpoint Communication: When a packet is sent from an endpoint in one leaf switch to an endpoint in another leaf switch, the original Ethernet frame is encapsulated with a VXLAN header, including the VNI. The packet is then forwarded through the ACI fabric based on the VNI, allowing logical segmentation and isolation of traffic.
- Decapsulation: At the receiving leaf switch, the VXLAN header is stripped off, and the original Ethernet frame is delivered to the destination endpoint.
- MP-BGP (Multiprotocol Border Gateway Protocol):
MP-BGP is a routing protocol used in Cisco ACI to exchange routing information and support the operation of the VXLAN-based overlay network.
- MAC and IP Address Learning: MP-BGP carries information about the MAC addresses and IP addresses associated with endpoints within the ACI fabric. This information is learned from the spine switches and distributed to all the leaf switches in the fabric, enabling them to build forwarding tables.
- Leaf-to-Leaf Communication: MP-BGP is used by the leaf switches to exchange routing information and MAC/IP address reachability with each other. This allows leaf switches to determine the optimal paths for forwarding traffic within the fabric.
- External Connectivity: MP-BGP is also used to exchange routing information between the ACI fabric and external networks, such as the underlay network or other data center networks. This enables the ACI fabric to connect to external devices and exchange traffic beyond the fabric boundaries.
In summary, the control plane in Cisco ACI is responsible for managing the fabric’s operation and distributing policies, while the data plane handles the forwarding of encapsulated traffic between endpoints using VXLAN. MP-BGP plays a crucial role in exchanging routing and reachability information within the ACI fabric and connecting the fabric to external networks. Together, these components work together to provide a scalable, policy-driven, and efficient networking infrastructure within the ACI framework.
MP-BGP
MP-BGP (Multiprotocol Border Gateway Protocol) operates at the control plane in Cisco ACI. It is responsible for exchanging routing information and facilitating communication between the ACI fabric components, including the leaf switches and spine switches.
In the context of Cisco ACI, the control plane is primarily concerned with managing and maintaining the overall operation of the fabric, including policy distribution, endpoint learning, and routing. MP-BGP serves as the control protocol within the fabric, allowing the ACI switches to exchange routing information and MAC/IP address reachability.
MP-BGP carries information about MAC addresses, IP addresses, and routing tables between the ACI switches. It enables the leaf switches to learn about the available routes and MAC/IP address reachability, which they use to build forwarding tables for traffic within the fabric.
By operating at the control plane, MP-BGP facilitates the establishment and maintenance of the fabric’s routing infrastructure, ensuring efficient forwarding of traffic based on learned routes and policies. It enables communication and coordination among the ACI fabric components, contributing to the overall functionality and scalability of the SDN-based network.
MANAGING ACI
Managing the different designs in Cisco ACI, including single-pod, multi-pod, multi-site, and ACI Anywhere, involves the use of the APIC (Application Policy Infrastructure Controller) and APIC Cluster. Here are the pros and cons of each aspect:
- APIC:
Pros:
- Centralized Management: The APIC provides a centralized management and policy enforcement interface for the entire ACI fabric. It offers a unified view and control over the fabric’s resources, policies, and services.
- Simplified Operations: The APIC abstracts the underlying complexity of the fabric, providing an intuitive graphical user interface (GUI) and programmable interfaces (APIs) for streamlined configuration, monitoring, and troubleshooting.
- Policy-Based Automation: APIC enables policy-driven automation, allowing administrators to define and enforce network policies across the fabric. This simplifies application deployment and ensures consistent behavior across the network.
Cons:
- Single Point of Failure: In a single APIC deployment, if the APIC controller fails, it may impact the management and control functions of the entire fabric.
- Scalability: A single APIC may have limitations in terms of scalability for larger and more complex deployments.
- APIC Cluster:
Pros:
- High Availability: APIC Cluster consists of multiple APIC controllers working together in an active-active mode. It provides redundancy and ensures continuous operation even if one or more APIC controllers fail.
- Load Distribution: APIC Cluster distributes the management and control plane functions across multiple controllers, allowing for load balancing and increased performance.
- Scale-Out Capability: APIC Cluster enables the fabric to scale by adding more APIC controllers to the cluster, accommodating larger deployments and increased management requirements.
Cons:
- Increased Complexity: APIC Cluster introduces additional complexity in terms of configuration, synchronization, and inter-controller communication. It requires proper planning and configuration to ensure smooth operation.
- Additional Hardware: APIC Cluster typically requires additional hardware resources, such as dedicated servers, to support the clustering functionality.
In terms of managing the different designs:
Single-Pod Design: This design offers simplified management due to the smaller scale and reduced complexity. However, it may lack the redundancy and scalability required for larger deployments.
Multi-Pod Design: Managing a multi-pod design involves interconnecting the pods and maintaining consistent policies across them. It provides scalability and redundancy, but it introduces additional complexity in terms of inter-pod communication and policy synchronization.
Multi-Site Design: Managing a multi-site design includes interconnecting geographically dispersed sites and ensuring consistent policies and connectivity. It offers disaster recovery and geographical distribution benefits but involves complex configuration and inter-site communication.
ACI Anywhere: Managing ACI deployments across multiple environments, including on-premises data centers and public clouds, requires coordinating policies and connectivity. It offers flexibility and hybrid cloud support but may involve connectivity challenges and additional considerations for cloud resources.
In summary, the APIC provides centralized management and policy enforcement, while the APIC Cluster offers high availability, scalability, and load distribution. The choice of design and the use of APIC or APIC Cluster depend on factors such as scalability requirements, redundancy needs, management complexity, and disaster recovery considerations specific to the organization’s data center and networking infrastructure.
MULTI-POD:
MULTI-SITE:
CISCO COMPARISON: