There’s a lot you need to think about when designing your Splunk environment. I’m hoping to keep adding to this blog post. One important decision is to decide to use a Universal or Heavy Forwarder. Universal forwarders are used to collect data from a number of sources and send it to Splunk indexers. Below is some info on the differences that came from a Splunk Conference. The recommendation is to use a Universal Forwarder.

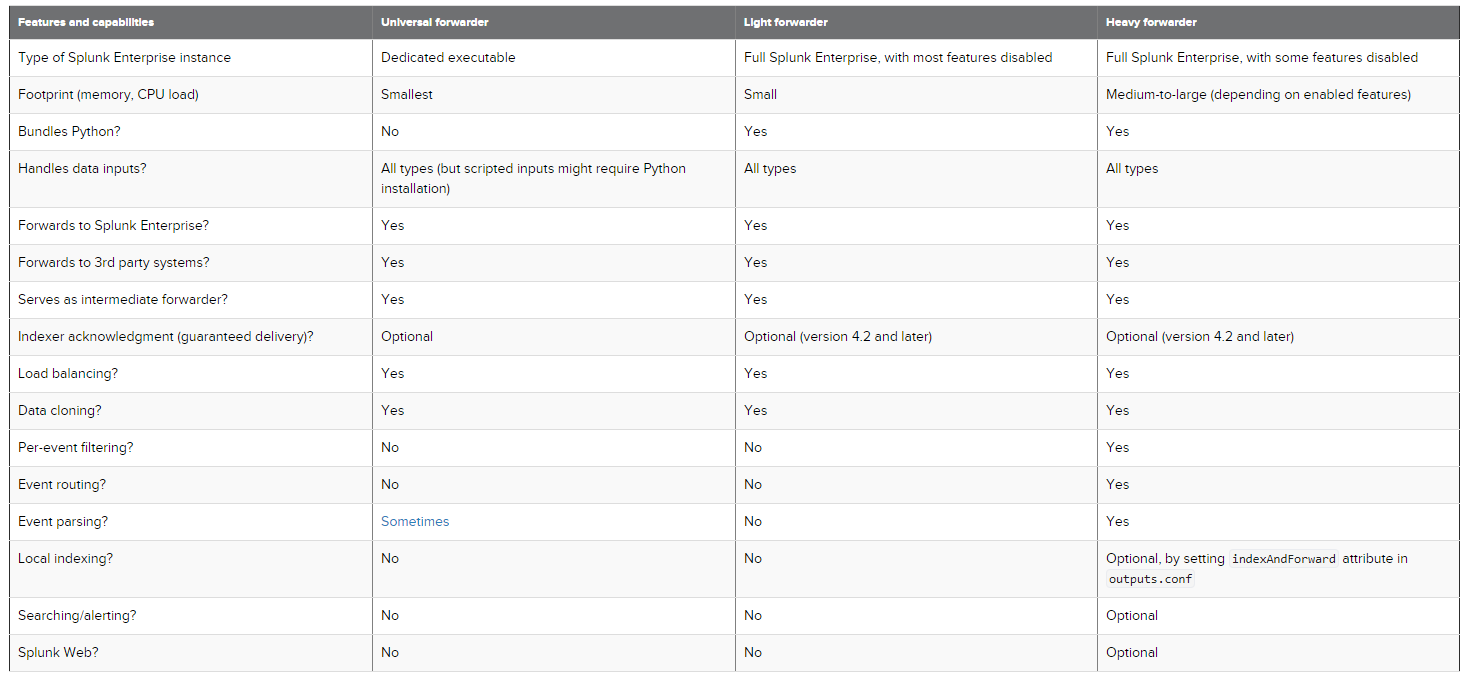
Below you can see a nice comparison between the different forwarders:
Performance benefits when choosing Universal Forwarders:
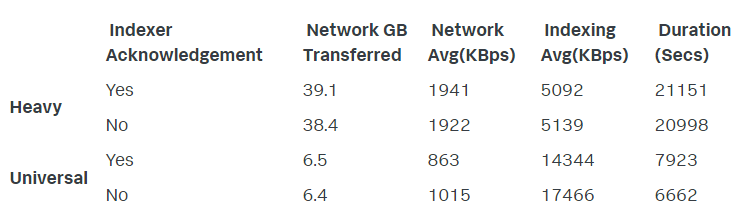
The key takeaways are:
The amount of data sent over the network was approximately 6 times lower with the Universal Forwarder.
The amount of data indexed per second was approximately 3 times higher when collected by a Universal Forwarder.
The total data set was indexed approximately 6 times quicker when collected by the Universal Forwarder.
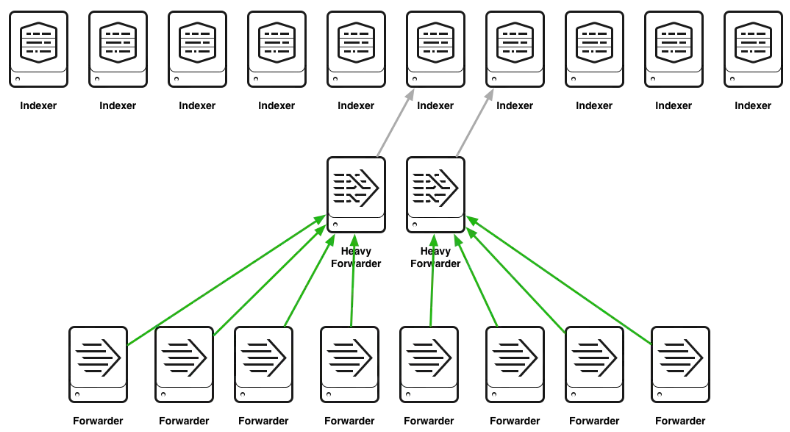
#DO NOT DO THIS
Below is what you do NOT want to do when designing the forwarders because it creates a bottleneck:
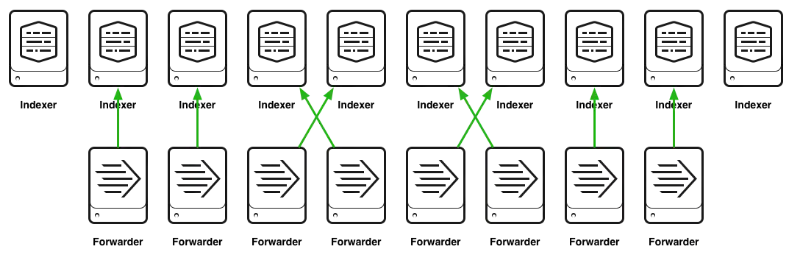
#DO THIS
Below is what you want to do when designing the forwarders:
#PORTS AND COMPONENTS WITH DIAGRAMS
Ports and Components:
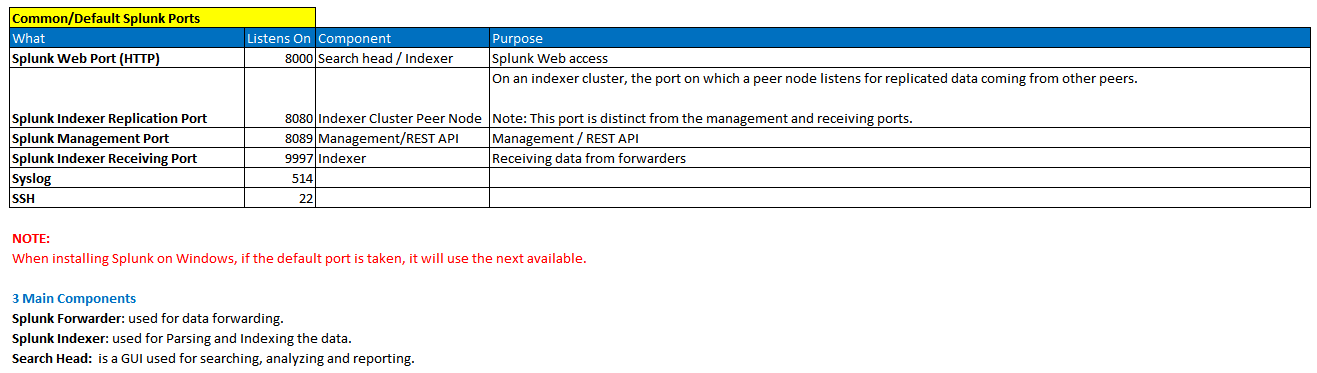
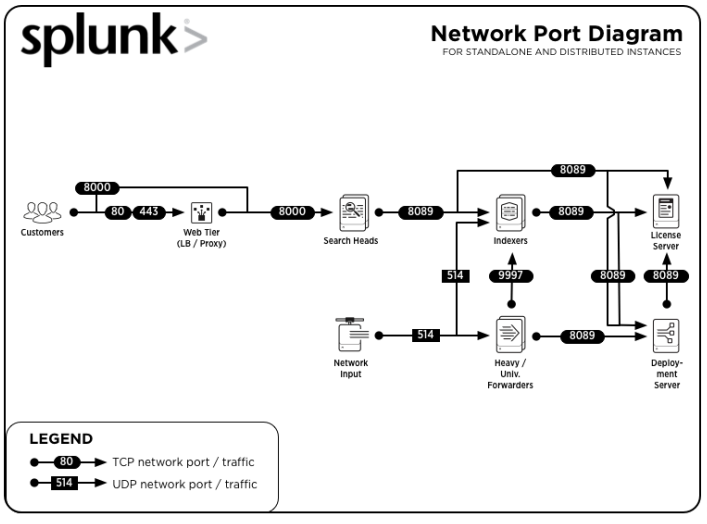
Diagrams:
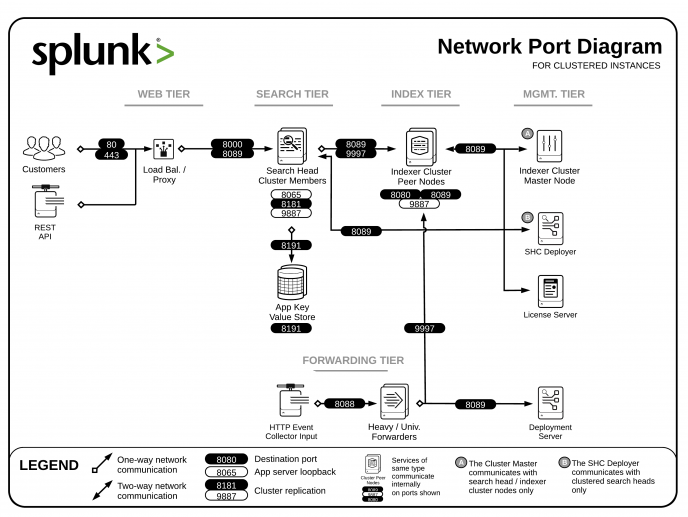
#EXAMPLE DESIGN USED
Below is a design that I’ve done in the past using Microsoft Azure but it’s the same for AWS:
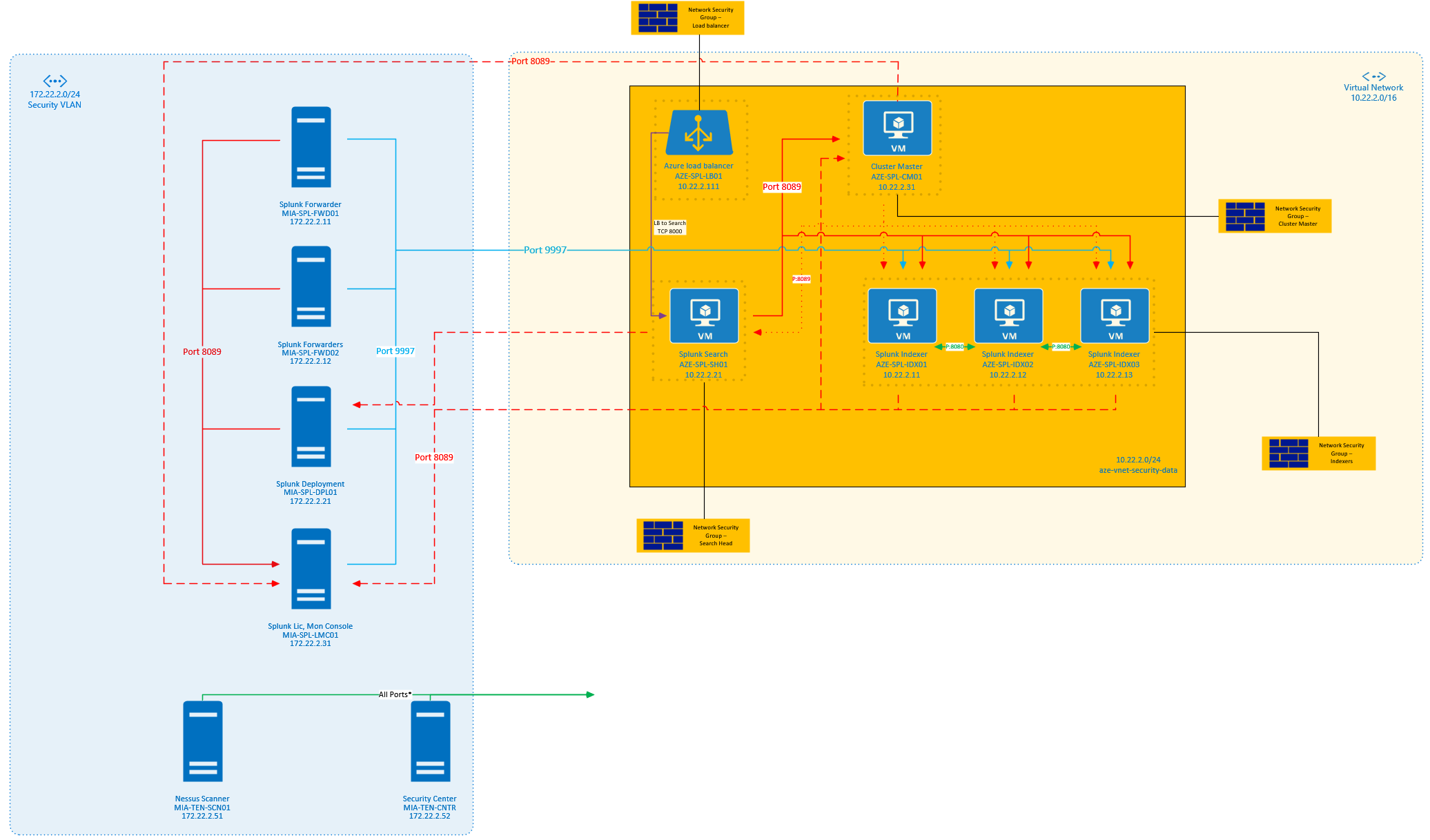
#HARDWARE SPECS
On-Premise Servers
• 2 nodes; 1 for Deployment Server + 1 for Monitoring Console (DMC), and License Master (LM)
o 16 cores at 2+ GHz CPU
o 16GB RAM
o 2 x 300GB, 10,000 RPM SAS hard disks, configured in RAID 1
o 10GB Ethernet NIC
o 64-bit Red Hat Enterprise Linux distribution
• 2 Universal Forwarders (Syslog, etc.) aggregation nodes
o 24 cores at 2+ GHz CPU
o 128 GB RAM
o 2 x 400 GB Solid State Drive, Redundant Array of Independent Disks (RAID) 0 or 1+0
o 10GB Ethernet NIC
o 64-bit Red Hat Enterprise Linux distribution
Azure Servers
• 3 Indexer
o Intel 64-bit chip architecture
o 16 cores at 2+ GHz CPU
o 128GB RAM 32TB disk w/ 900 IOPS (multiple partitions) to accommodate 365-day retention
o 10Gb Ethernet NIC with optional second NIC
o 64-bit Linux
• Search Head
o Intel 64-bit chip architecture
o 16 CPU cores at 2Ghz or greater speed per core, 48GB RAM
o 2 x 300GB, 10,000 RPM SAS hard disks, configured in RAID 1
o 10Gb Ethernet NIC, optional 2nd NIC for a management network
o 64-bit Linux
• Cluster Master (CM)
o 16 cores at 2+ GHz CPU
o 48 GB RAM
o RAID 0 or 1+0
o 64-bit OS installed
#SPREADSHEET
I’m attaching the spreadsheet for this design. In the spreadsheet, there’s also a Daily Log Sizing estimator which comes in handy. 🙂
[easy_media_download url=”https://cordero.me/docs/Splunk_Environment_Information_blog_v1.xlsx”]
Design is dependent on the environment but I hope it helps at least get started in the right direction.
#BEST PRACTICES
Basics:
Multiple clustered search-peers (indexers) boost data-ingest and search performance. This technique saves search time and provides some data ingest and availability redundancy if a single server fails.
There are one or more search heads. Any search request will be distributed across all set search-peers, improving search performance.
Splunk’s Enterprise Security (ES) application is supported via a separate search head.
Deployment Server: A deployment Server is a server that allows you to deploy software. This system can be used in conjunction with other Splunk services or on its own. A stand-alone solution is essential for large deployments. Typically, this system serves as the License Master.
Master Node: Node that serves as the master. The Deployment server is usually co-located with this system. A stand-alone solution is essential for large deployments.
Architecture and Design:
Make indexes and source types a priority. It won’t be easy to adjust these two items afterward. Indexes and sourcetypes aid data management.
Source type can be used to categorize data based on their similarity. If the events are generated by the same device and have the same format, they are most likely from the same source.
Try to collect occurrences that are as close together as possible (in terms of geography and network location). These events can be gathered using a Splunk Universal Forwarder and then forwarded to indexers, which could be located in a central place.
Keep search heads as close as possible to indexers. The search head will be able to access the events more quickly as a result of this.
To maintain accuracy and decrease troubleshooting time, use a consistent naming convention on the Splunk Search Heads and Indexers.
To ensure success, carefully plan the implementation of Windows event collection (Event logs and Performance data). Many Windows event collection methods have limits, such as 512 or 1024-byte truncation of events. The Splunk Universal Forwarder does not have these constraints and may be used to collect Windows events from a large distributed enterprise reliably and effectively.
——We strongly advise you to use Splunk TA Windows.
——Consider using the Splunk add-on for Microsoft sysmon in addition to Splunk TA Windows for more detailed logging on important systems.
The entire team shares accountability. Instead of being spread over various departments, divisions, or companies, Splunk should be managed by a single team. Furthermore, because much of Splunk’s deployment necessitates a thorough understanding of its intended use, it is advised that the team that will be the primary user of Splunk also manage its deployment. In most cases, this translates to a more successful implementation.
——Use a License Master to manage your Indexer licensing, and don’t forget to include your search heads and any heavy/full forwarders.
Consider utilizing Deployment Server if you have a dispersed deployment with several Splunk search heads and forwarders. Using a deployment server can assist keep Splunk systems configured consistently and make configuration changes much easier (no having to touch every system).
Indexer clustering should be actively considered when implementing Indexers. Even if you only have one Indexer, starting with a master node to manage the Indexer’s configurations will make scaling to a multiple indexer system a breeze.
Use Splunk’s listening ports, which bind to specific back-end processes, with care and consistency. When Splunk starts, some of these are mentioned.
Verify the integrity of the data. Splunk collects and represents data with extreme precision; yet, if you provide it fraudulent or duplicate data, it may index it as well. Review your inputs regularly to ensure that your information is correct, your timestamps are exact, and no errors, such as duplicated or wrong events.
Authentication should be done through Active Directory (AD). To authenticate users, Splunk works nicely with Active Directory. This setup allows you to assign a user to a group in Active Directory and then map that group to a Splunk role. When this user logs into Splunk, they are given the capabilities and rights that the role has assigned to them. Role-based access controls are granular (RBAC). The Microsoft AD utility adsiedit.msc is excellent for searching an AD domain for important elements required for setting up AD auth on Splunk. On 2008 AD systems, this utility is installed by default, but on older versions of Windows, it must be installed manually as part of the RSAT package.
For Active Directory Integration, create a new OU. For Splunk to seek for groups in AD, you can specify a list of one or more bindgroupDNs when setting AD. If you provide Splunk the root directory for all groups, it may return hundreds or thousands of them. Furthermore, if you use existing groups, there may be many additional users in that group that you don’t want to have Splunk access. If you construct new base ou (e.g. OU=splunkOU) in AD and then build your access groups beneath it, e.g. (OU=server admins,OU=splunkOU, OU=network admins,OU=splunkOU), you can set the bindgroupDN to “splunkOU” to reduce the number of returned groups and users with Splunk access.
Index Data Migration can be tricky, and you must proceed with caution because you risk erasing and disabling your data. It’s recommended that you contact Splunk support or have PS assist you. If you must do it manually, study the documentation and learn how the bucket structure works. You may also look at this replies post for further information.
Consider the consequences of directly parsing data on your Indexers or employing Intermediate Heavy Forwarders. There were several changes in Splunk 6.2 to what would require a restart on the Indexers, and Indexer Clustering minimizes this even more. Heavy Forwarders are generally discouraged from doing anything other than bringing in data via apps or APIs.
——The number of systems to handle is reduced by moving away from Heavy Forwarders.
——Because there are no heavy forwarders, you will always know where your data is being parsed (the Indexer).
——Heavy Forwarders can still be useful in some situations. A Heavy Forwarder can be used to reduce CPU stress on Indexers when performing a large number of parse-time operations on data, such as huge quantities of Index, Host, and Sourcetype renaming. This is not required in most cases and adds to the complexity of deployments.
Consider utilizing an Intermediate Universal Forwarder in circumstances where remote offices have limited bandwidth or have unreliable network connections. This reduces the number of connections on a bandwidth-limited network and, if needed, improves rate-limiting management.